In the following, we go through the files created by GPMelt after running the example of the tutorial, i.e. the ATP 2019 dataset with a subset of 16 IDs.
As a comparison, we use the published results that can be found on Zenodo , saved under the name ATP2019/prerun/GPMelt_p_values.rds.
Note: The published results have been obtained with a previous version of the implementation that did not use Nextflow. The implementation has been fully rewritten to be user-friendly and provides a lot of the results for free, when we previously had to do some work.
For example:
ATP2019/prerun/GPMelt_p_values.rds is obtained from ATP2019/GPMelt_results/Ratios_NullDataset.rds and ATP2019/GPMelt_results/Ratios_RealDataset.rds, as explained in the code on gitlab in Analysis/ATP2019/ATP2019_Analysis.qmd.
Similarly, we will see that Nextflow provides us with a report about resource requirements which was previously done manually, as exemplified on gitlab in Analysis/ComputationalCost/ComputationalCost.qmd.
2 Checking the convergenve
A good practice is to first check the convergence of the fits. For this, we use the loss associated to the fit of the full model \(\mathcal{M}_1\).
As explained here, the parameters of the model are estimated by minimising the negative log marginal likelihood of the observation.
The negative log marginal likelihood of the observation is a loss function which measures the goodness-of-fit of a model.
The algorithm is trying to minimise this loss. The convergence is assumed to be reached when the loss remains constant for a large number of iterations.
As a quick check, you can start by looking at your favorite proteins in the list of plots. Go in the folder Results_ATP2019/Plots and select your proteins. The first plot (which should be page two) represents the evolution of the loss with the number of iterations.
To proceed to a more general check, we can load the file full_hgpm_fit_loss_values_df.csv.
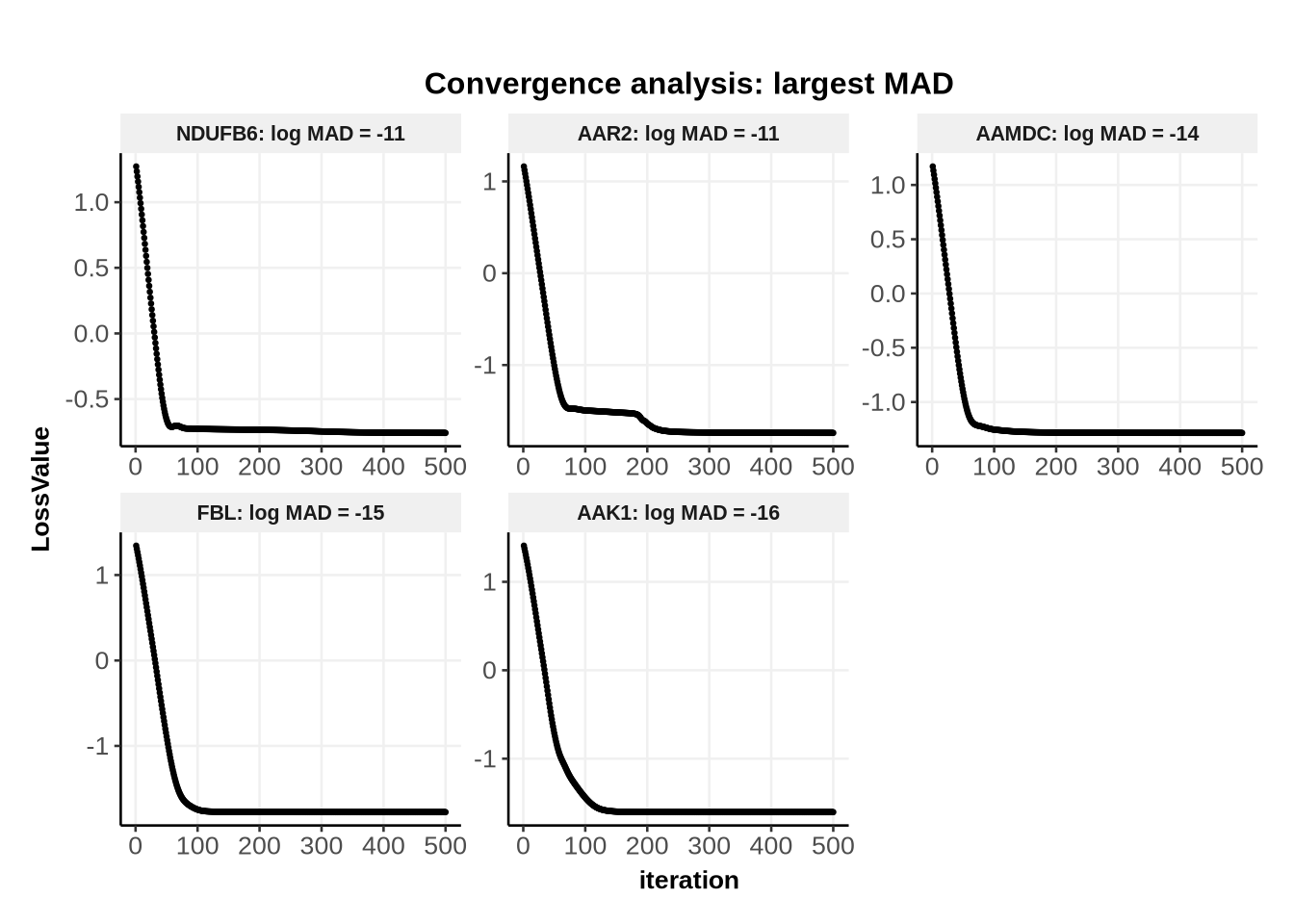
Because we have only 16 IDs, we can look at one glance the convergence status of all IDs. Here we can see that AARS2 did not converge as quickly as the other IDs, as there was likely another local optimum on which the algorithm got stuck for a bit.
2.2 Assessing the stability of the convergence
If we have more IDs, we can’t really plot and check the convergence for thousands of them.
Below is a suggestion for what can be done instead. Feel free to use additional or other summary statistics to check the overall convergence.
We first check if the loss value takes the value NA, which means that there is some sort of problem.
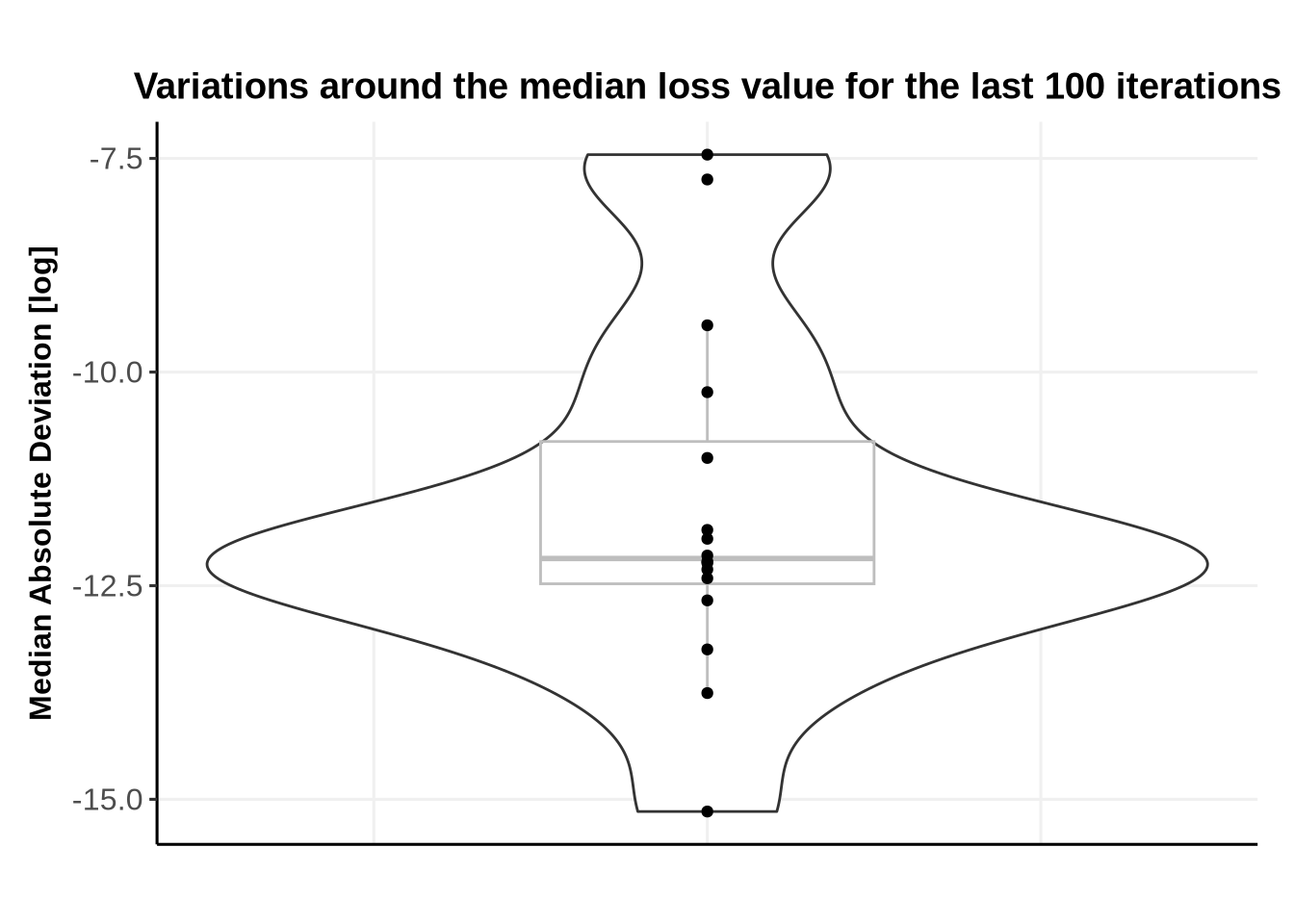
We then compute the median loss over the last 100 iterations, along with the Median Absolute Deviation (MAD). Large deviations around the median value usually indicate lack of convergence.
Below we see that there is no NA values in the loss.
ggplot(FinalIterations, aes(x=0,y=log(MADLoss)))+geom_violin(width =0.3) +geom_boxplot(width =0.1, color="grey", alpha=0.2)+geom_point()+#geom_jitter(width=0.1, alpha=0.9) + # geom_jitter can be used when more data points are presentggtitle(paste0("Variations around the median loss value for the last ", N_last_iterations, " iterations"))+xlab("")+ylab("Median Absolute Deviation [log]")+theme_Publication(base_size =12)+theme(axis.text.x =element_blank(),axis.ticks.x =element_blank(),legend.position ="bottom")
2.3 Checking more specifically the IDs with the worst convergence
Here all values are very small. However, it can still be informative (when dealing with much more IDs) to plot the convergence for the IDs with the largest MAD.
Alternatively, the user can select all IDs with MAD above a certain threshold, or a certain fraction of the largest MAD, etc…
For IDs which did not converge, the user can
rerun the fit on this subset with more iterations or an alternative model specification,
exclude these IDs from the analysis, if the lack of convergence is due to these IDs being too noisy for example.
3 The \(\Lambda\) statistics
After checking that our fits converged, and hence that the final results are meaningful, we can start looking at the results.
We start by looking at the GPMelt’s statistic \(\Lambda\).
As explained here, we define \(\Lambda\) to assess if two conditions present significantly divergent melting behaviour. This statistic is given by: \[ \Lambda = -2 \log \frac{p(Y \mid T, \theta^{MLE-II}, \mathcal{M}_0)}{p(Y \mid T, \theta^{MLE-II}, \mathcal{M}_1)} \ . \] This can be rewritten 1 in terms of loss as:
\[ \Lambda = -2 \cdot ( \text{loss}(\mathcal{M}_1) - \text{loss}(\mathcal{M}_0) )\] Here \(\text{loss}(\mathcal{M}_1)\) represents the loss value for model \(\mathcal{M}_1\) at the last iteration (similarly for \(\mathcal{M}_0\)). Because we directly use the loss valus in the computation of \(\Lambda\), \(\Lambda\) is not valid if the fit did not converge.
Hence \(\Lambda\) can be interpreted as comparing the goodness-of-fit of model \(\mathcal{M}_0\) and \(\mathcal{M}_1\).
The better the goodness-of-fit, the lower the loss value. Equivalently, this means that the larger \(\Lambda\), the more evidence we have against the null hypothesis that \(\mathcal{M}_0\) is enough to fit the data, compared to \(\mathcal{M}_1\).
3.1 Loading the results
The loss values for each model can be found in the p_values_*_wise.csv dataset ( with *standing for ID or dataset).
p_values_subset contain the p-values obtained on the subset of 16 IDs, and p_values_fulldataset contains the p-values previously obtained (published) considering the full ATP 2019 dataset.
3.2 Arrange and combine the two datasets
In the former implementation, we saved the log marginal likelihood (denoted mll), while we now save the loss. The link is simple: \(\text{loss} = - \text{log marginal likelihood}\).
3.3 Compare the results of the former and current implementation
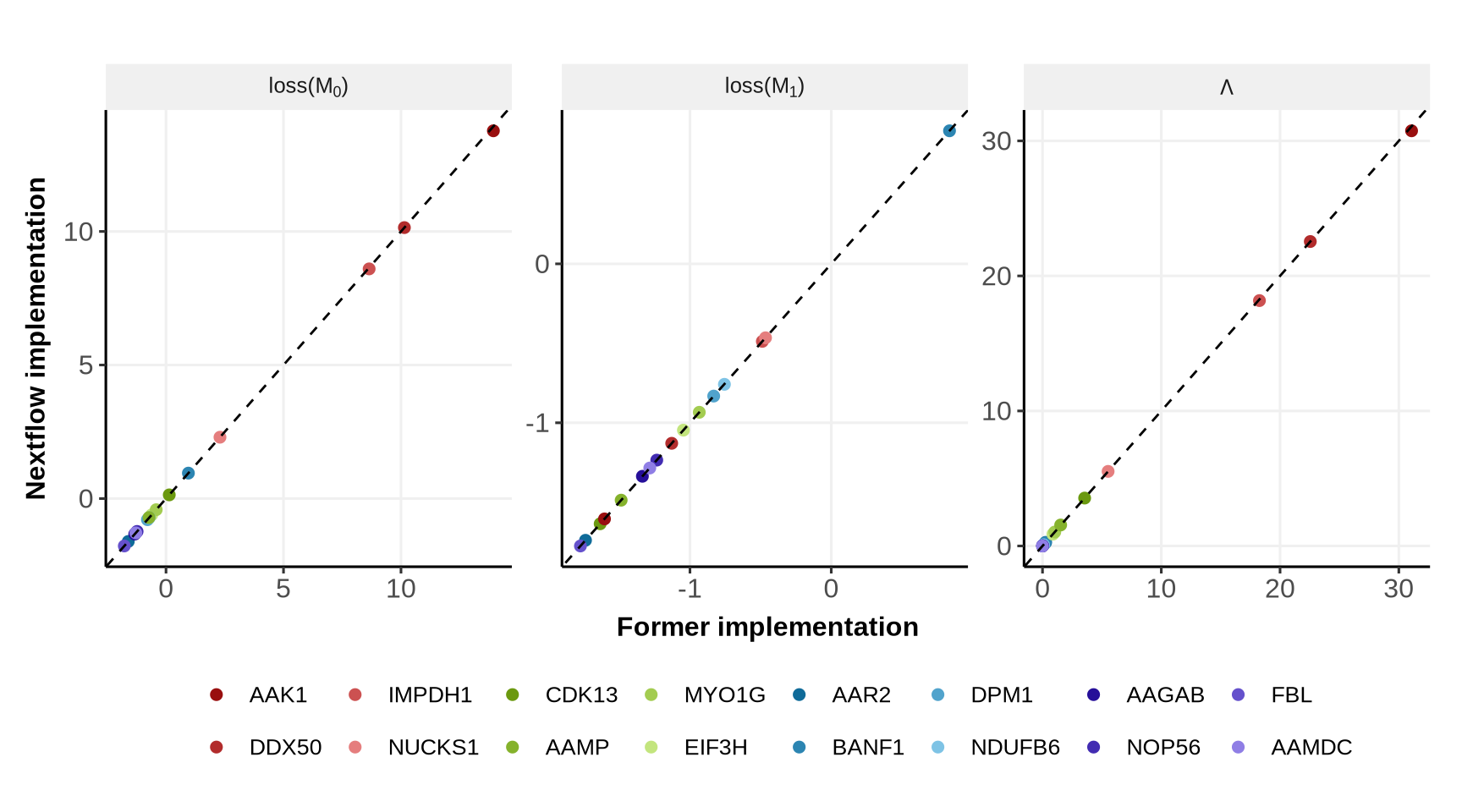
We now compare \(\text{loss}(\mathcal{M}_0)\) (loss_joint_model), \(\text{loss}(\mathcal{M}_1)\) (loss_full_model) and the statistic \(\Lambda\) (LikelihoodRatio) for the former implementation (the one used for the published results) and the new implementation using Nextflow.
Note: the variable name LikelihoodRatio might be confusing given that \(\Lambda\) is not a standard likelihood ratio test, however it is a ratio of (marginal) likelihoods.
We first select a colorblind palette from the colorBlindnesspackage:
Below we see that the new implementation with Nextflow provides the same results than the former implementation (dotted line is the line y=x, IDs’ colors are ordered by \(\Lambda\) values, from red to purple).
Having checked that the fits converged and that the \(\Lambda\) values are valid, we can now have a look at the fits. Especially, in our case, we have only 16 IDs so we can plot the fits for all of them. In general, you may be more interested in plotting the IDs with the largest \(\Lambda\) values and/or the smallest p-values.
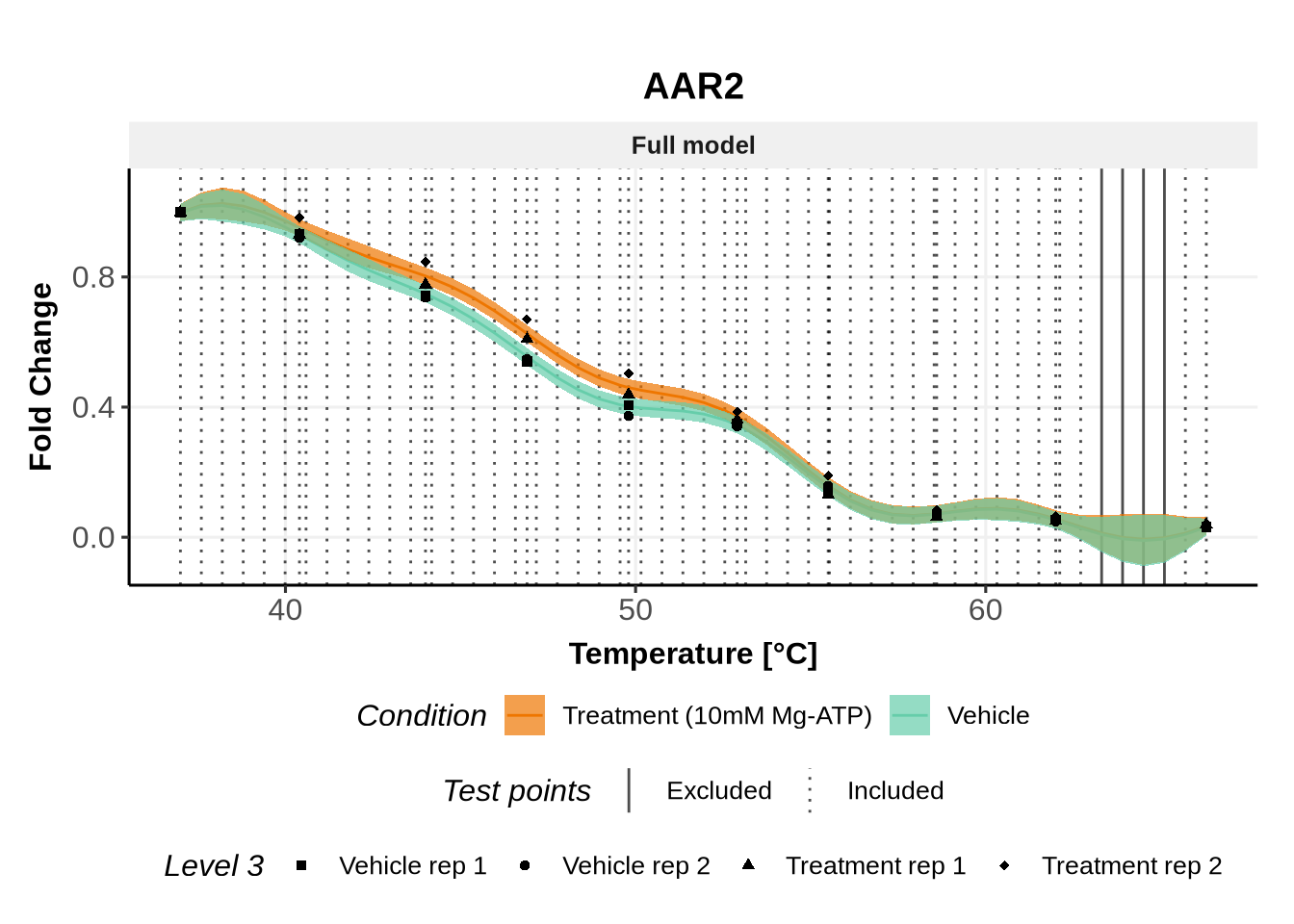
The fits are directly provided as output of the Nextflow pipeline. Go in the folder Results_ATP2019/Plots and select a protein: the plot on the last page should represent the fits for all curves comparisons performed for this protein.
We explain here how we can plot the fits using the output files starting with prediction. If the selected hierarchical model has \(L\) levels, then you should find \(L\) files starting with prediction_full_hgpm_ and \(L\) files starting with prediction_joint_hgpm_.
4.1 General variables
Code
custom_labeller <-function(value) {paste0( Hmisc::capitalize(value), " model")}# create a list to store the plots of each levelall_plots <-vector(mode ="list", length =length(order_levels_1))names(all_plots) <- order_levels_1for(i inseq_along(order_levels_1)){ all_plots[[i]] <-list("Level_1"=NA,"Levels_1to2"=NA,"Levels_1to3"=NA)}
4.2 Top level of the hierarchy
We start by loading the datasets.
Code
prediction_full_hgpm_Level_1 <-read.csv("NextFlow/Results_ATP2019/prediction_full_hgpm_Level_1.csv") prediction_joint_hgpm_Level_1 <-read.csv("NextFlow/Results_ATP2019/prediction_joint_hgpm_Level_1.csv") # if some scaling has been computed, we load the scaled dataif(file.exists("NextFlow/Results_ATP2019/data_with_scalingFactors.csv")){ real_dataset <-read.csv("NextFlow/Results_ATP2019/data_with_scalingFactors.csv") }else{# if no scaling has been computed, then we can use the input data real_dataset <-read.csv("NextFlow/dummy_data/ATP2019/dataForGPMelt.csv") }
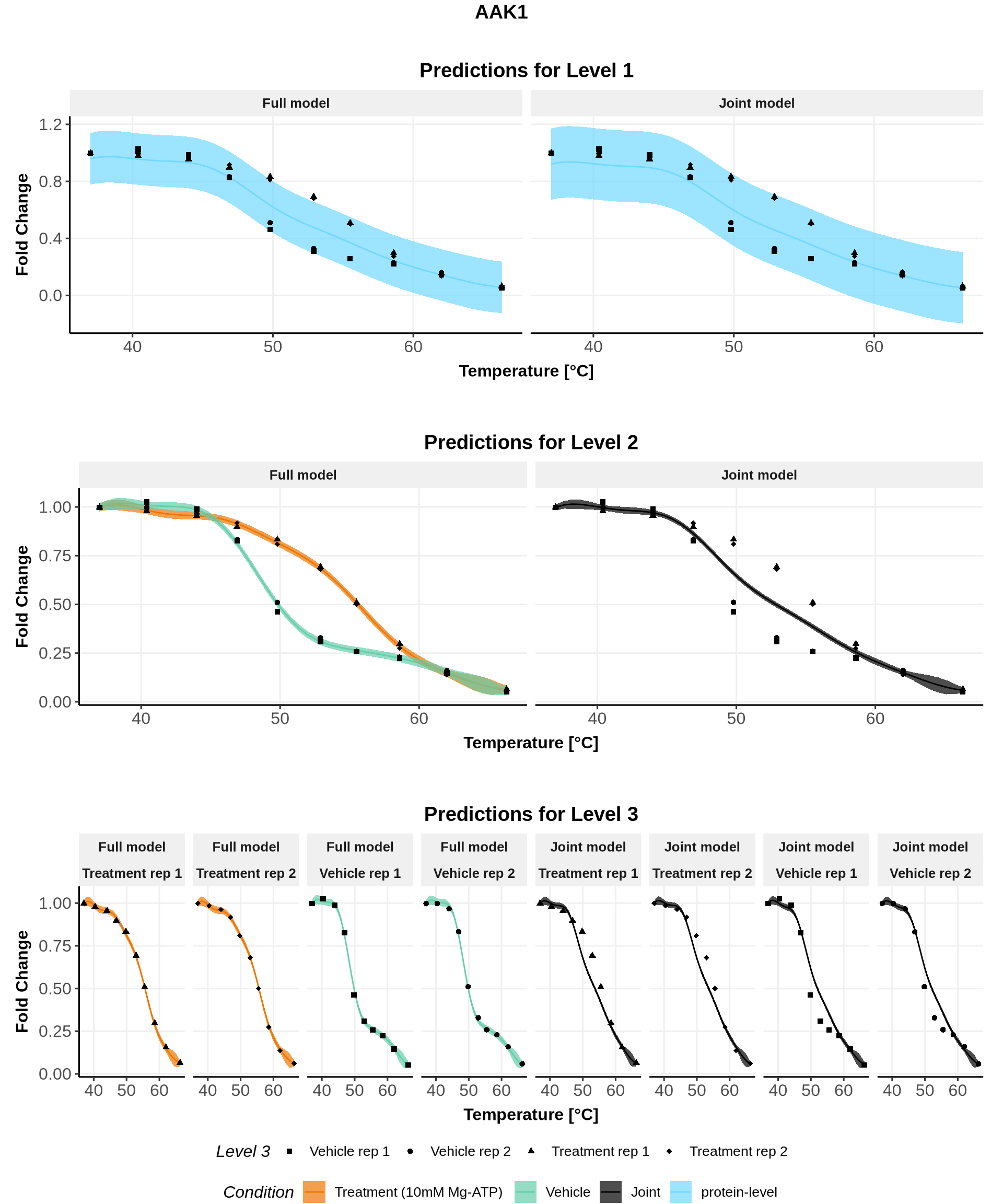
We will only plot the fits for the 5 IDs with the largest \(\Lambda\) values, but don’t hesitate to explore all fits!
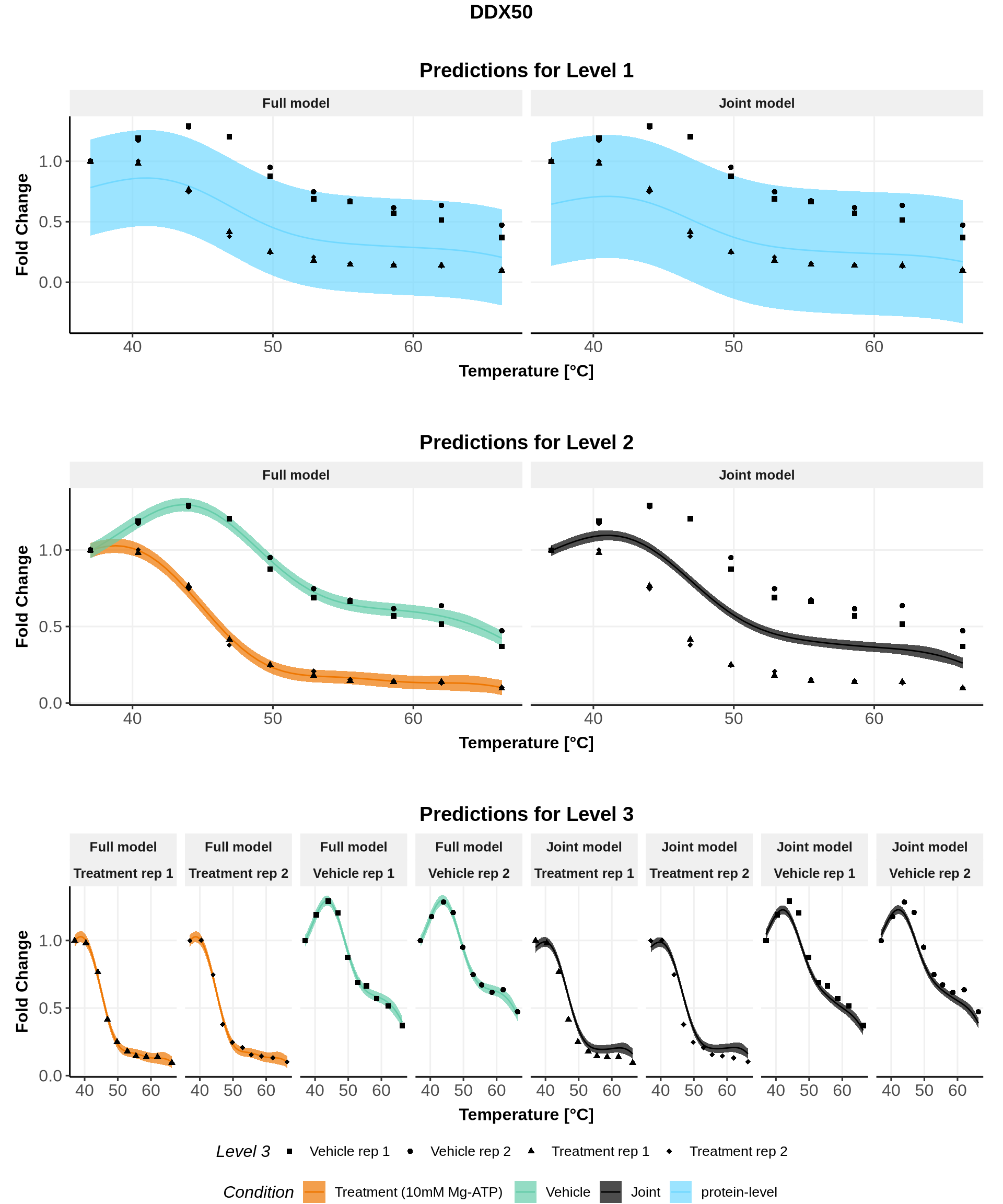
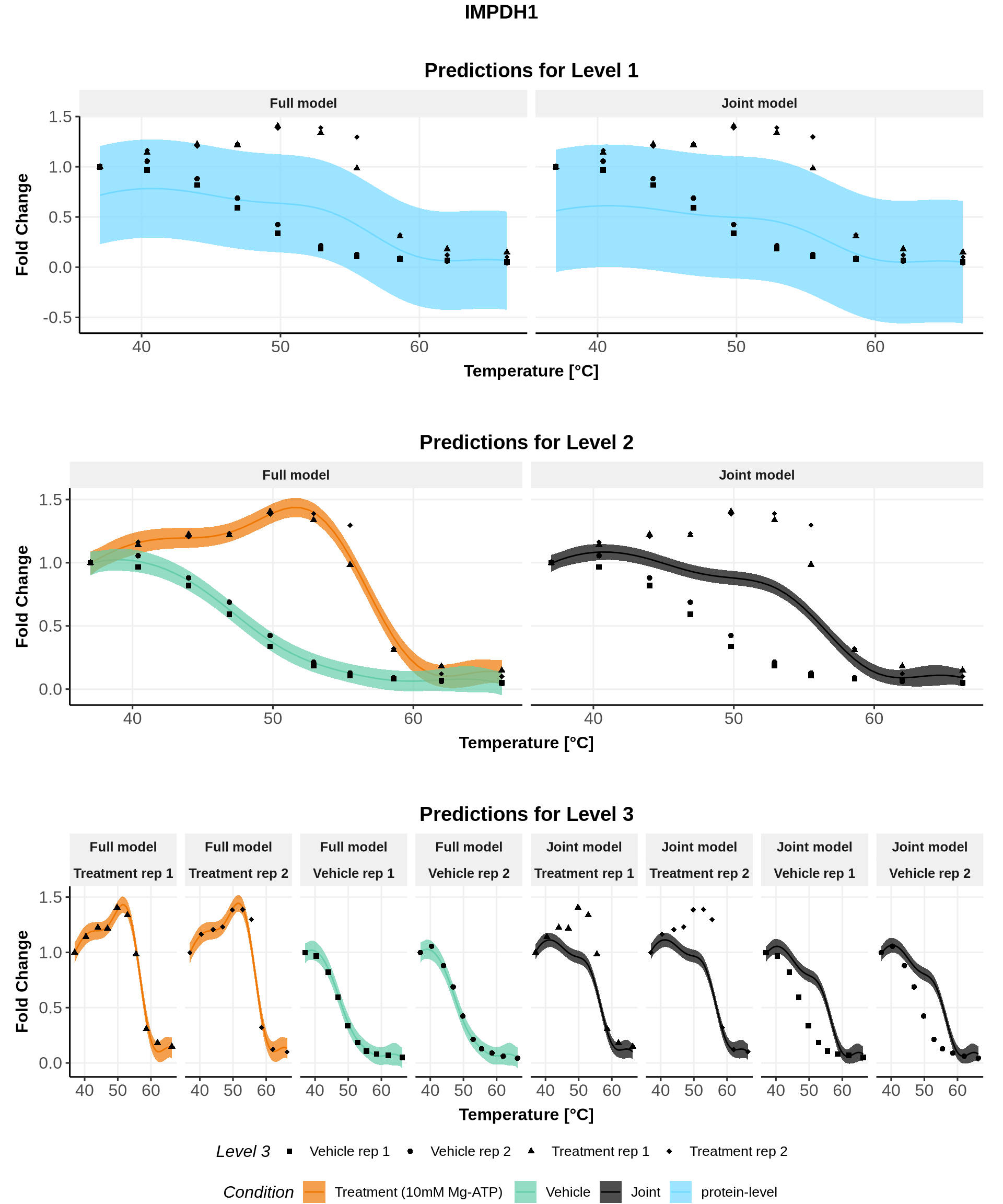
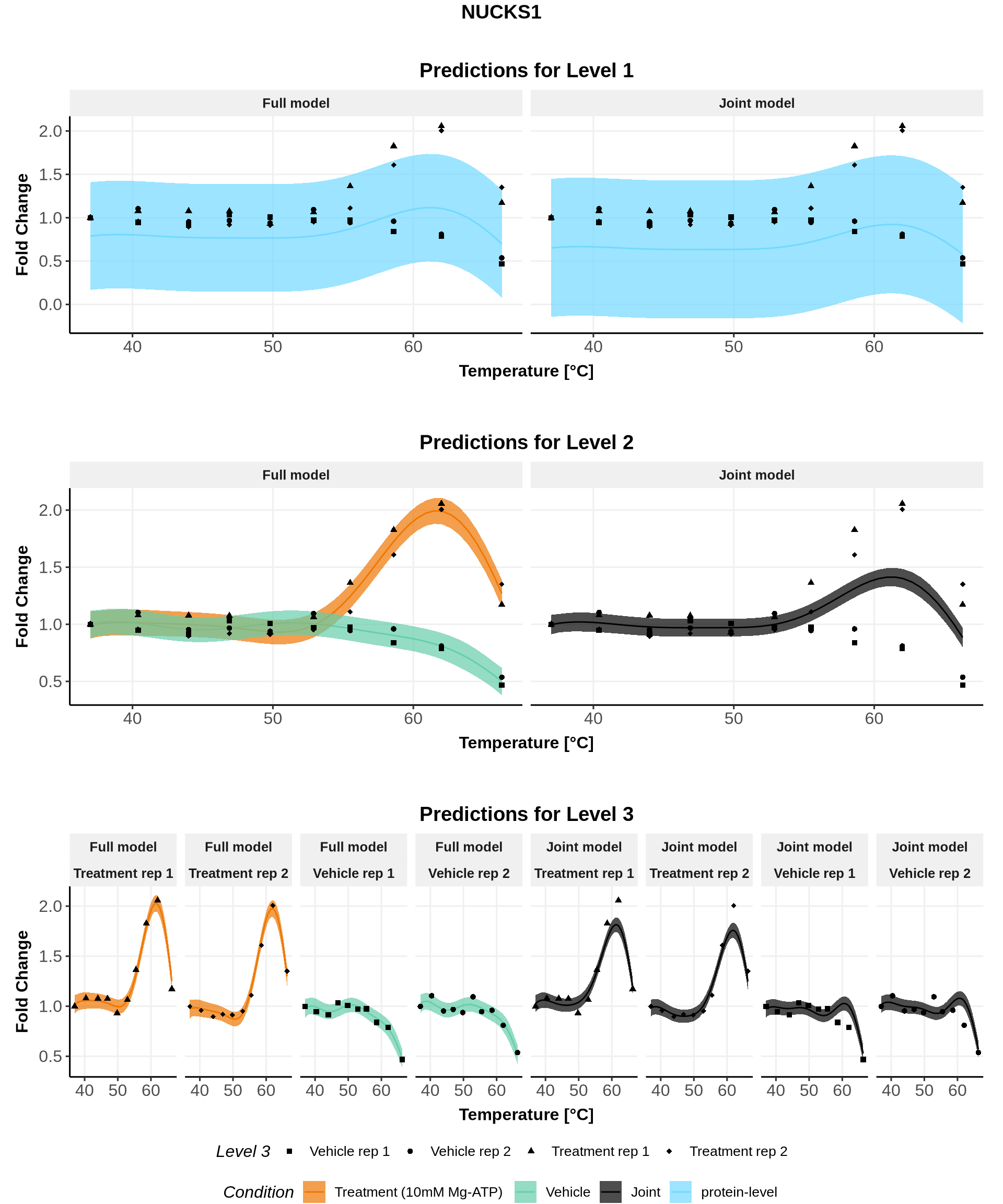
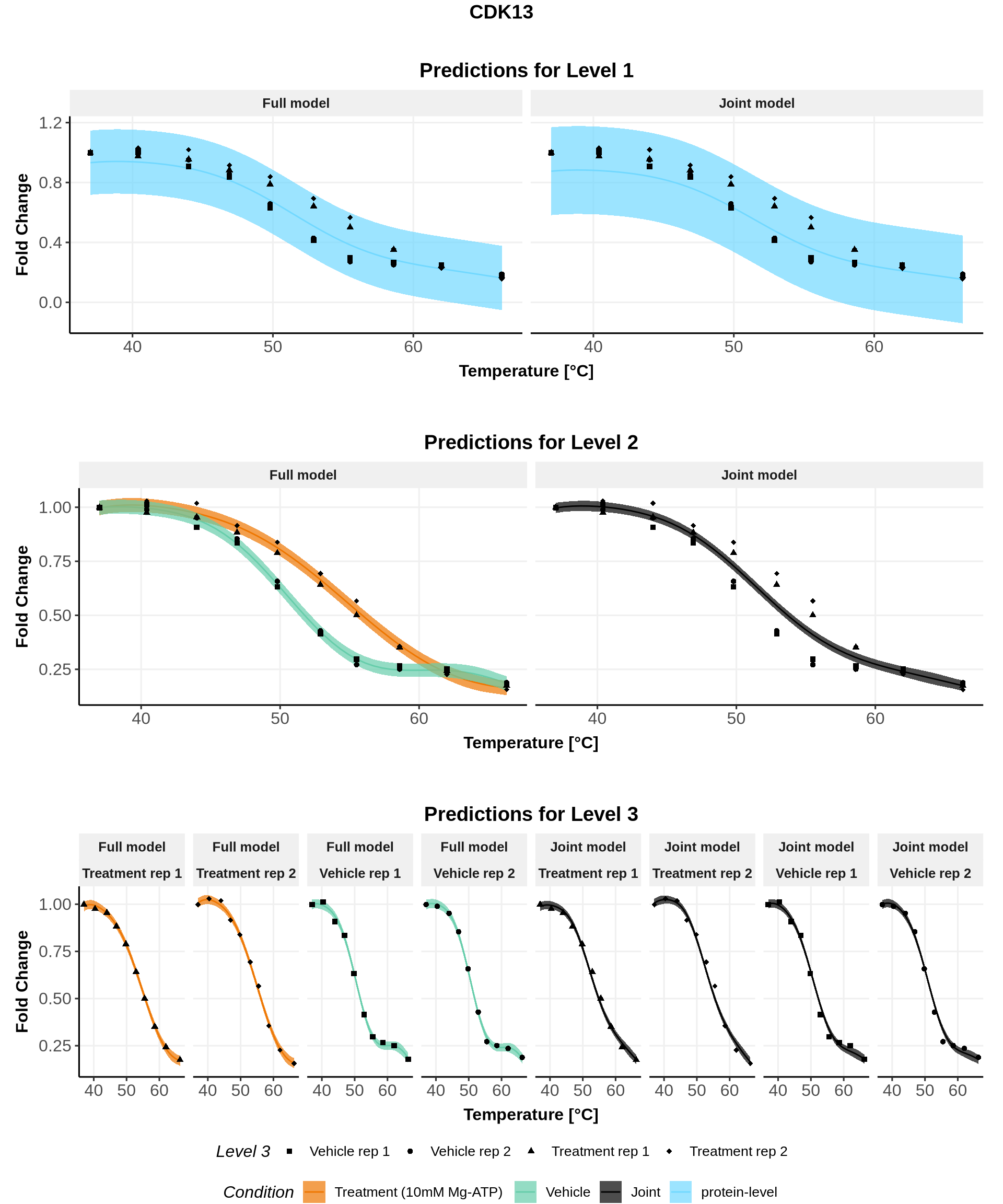
In these plots, we represent on the left the predictions obtained with the full model \(\mathcal{M}_1\) and on the right the prediction obtained with the joint model \(\mathcal{M}_0\).
Note: For both models, the parameters are the ones estimated for \(\mathcal{M}_1\)(for advanced users: see (Le Sueur, Rattray, and Savitski 2024) for an explanation).
Code
for(lev1 in order_levels_1[c(1:5)]){ full_hierarchy <-ggarrange( all_plots[[lev1]][["Level_1"]] +ggtitle("Predictions for Level 1"), all_plots[[lev1]][["Levels_1to2"]]+ggtitle("Predictions for Level 2"), all_plots[[lev1]][["Levels_1to3"]]+ggtitle("Predictions for Level 3"),ncol=1, nrow=3, common.legend =TRUE, legend="bottom") print(annotate_figure(full_hierarchy, top =text_grob(lev1,face ="bold", size =14)))}
5 Area between the curves
While the p-values indicate which changes are reproducible, the effect size might be of interest to biologists wishing to perform follow-up experiments.
Because the formerly used \(\Delta T_m = T_m^{\text{treatment}} - T_m^{\text{control}}\) (e.g. in the melting point analysis (Savitski et al. 2014) and NPARC (Childs et al. 2019)) is only valid for sigmoidal curves, we extend the definition of the effect size to any melting curve shapes, and any number of intersection points between the curves.
The thermal stabilisation (destabilisation) effect is thus only defined for cases where the treatment (control) melting curve remains uniformly above the other.
the mean of the posterior distribution for the condition level (here Level 2) of the full model (\(\mathcal{M}_1\)) can be used as proxy for the melting curve fit,
and the \(95\%\) confidence region inform on the certainty of this fit.
While we do not extrapolate the melting curves beyond the range \([T_{min}, T_{max}]\), missing observations within this range can introduce more uncertainty in certain temperature intervals. To address this, we propose incorporating the \(95\%\) confidence region into the ABC computation as explained in the next section.
5.1 Leveraging the information of the \(95\%\) confidence region
We will proceed as follows:
For the test points \(T^{*}\) (points in which the predictions are computed), calculate the median uncertainty for each condition of the protein, defined as the median of the differences between the upper and lower bounds of the \(95\%\) confidence region across all test points \(T^{*}\).
At any test point, if the difference between the upper and lower bounds of the \(95\%\) confidence region exceeds twice the median uncertainty, treat the predicted value of the fit (i.e of the mean) at this temperature as too uncertain, considering the posterior mean as not sufficiently reliable.
Exclude the union of these points (from both conditions being compared through the ABC) from the test points and compute the ABC using only the remaining, more reliable points.
Note: the \(95\%\) confidence region is provided in the prediction files, with variables conf_lower (lower bound of the \(95\%\) confidence region) and conf_upper (upper bound of the \(95\%\) confidence region). The posterior mean is given by the variable y in these files.
Code
CoeffUncertainty =2# you can increase this if you want to include only extremely reliable predictionsRegionOfAcceptableUncertainty <- prediction_full_hgpm_Levels_1to2 %>%mutate(Uncertainty =abs(conf_upper-conf_lower)) %>%group_by(Level_1, Level_2) %>%mutate(MedianUncertainty =median(Uncertainty)) %>%mutate(KeptTemperature = (Uncertainty <= CoeffUncertainty*MedianUncertainty ) ) %>%mutate(Diff =c(0, diff(KeptTemperature))) index2 =c(1,which(RegionOfAcceptableUncertainty$Diff !=0), nrow(RegionOfAcceptableUncertainty)+1)RegionOfAcceptableUncertainty$grp =rep(1:length(diff(index2)), diff(index2))
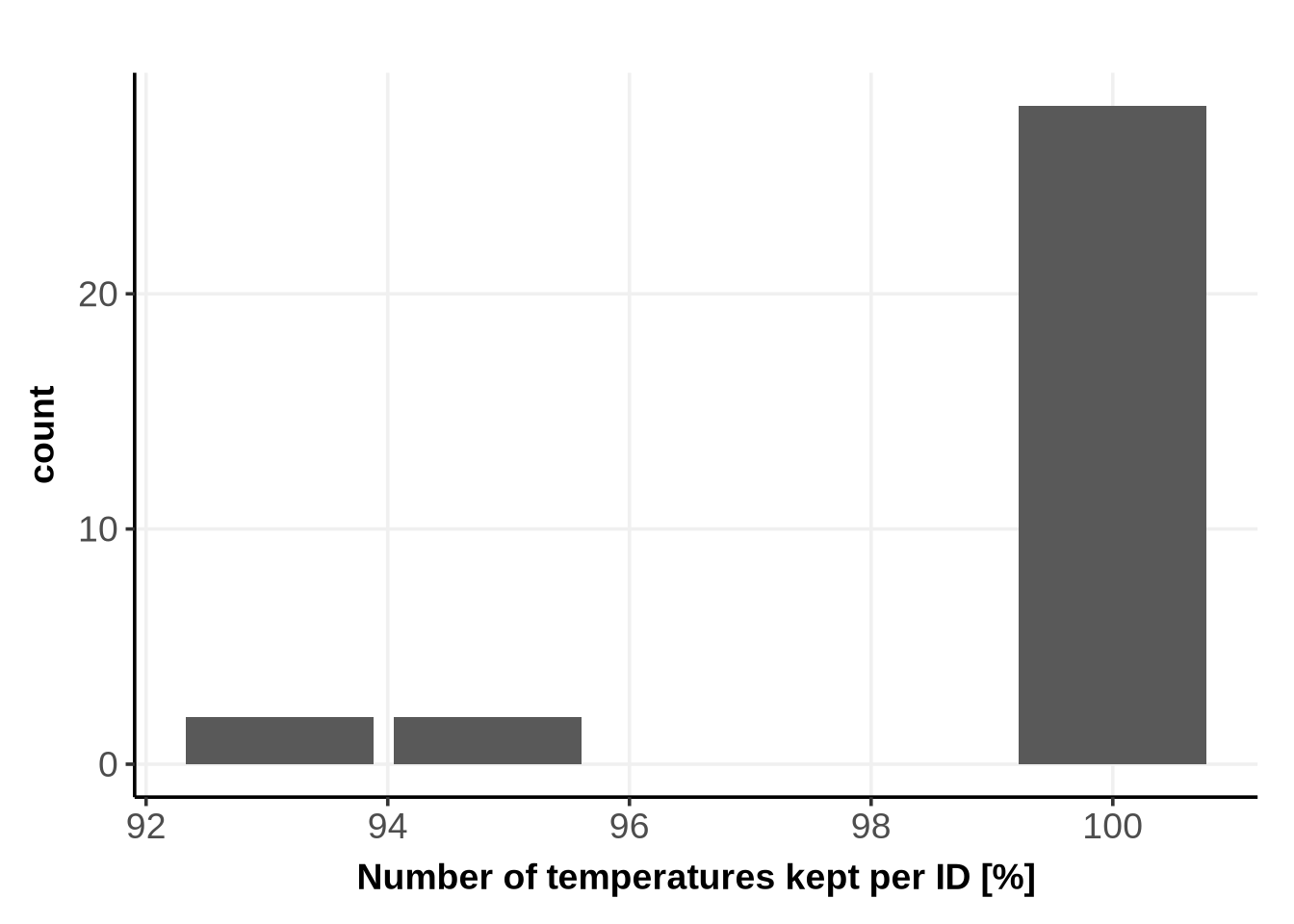
The following plot shows how many temperatures (in percentage) are defined as “certain enough” for the subsequent ABC computation:
RegionOfAcceptableUncertainty_N_temp %>%ggplot()+geom_bar(aes(x =100* (N_temp_kept/N_temp_total)) )+xlab("Number of temperatures kept per ID [%]")+theme_Publication()
Below are example of proteins for which some temperatures (represented by a vertical line) have been excluded from the ABC computation:
We propose to compute two different effect sizes: the absolute and signed ABC.
Indeed, the melting curves of two conditions can cross one to multiple times.
In this case, the signed ABC might be close to 0 (positive and negative area cancelling each other), but the absolute area between the curves will be large (see Section 8).
The signed ABC is useful if one is interested in the main direction of changes, i.e., primarily “destabilised” or “stabilised”.
Code
data_for_ABC_computation <-inner_join( # we need inner_join to only keep the temperatures which are present in both the control and the TTT# correspond to the fit of the control condition RegionOfAcceptableUncertainty %>%inner_join(data.frame(Level_2="Vehicle")) %>%filter(KeptTemperature)%>% dplyr::select(Level_1 , Level_2, x, y) , # correspond to the fit of the TTT condition RegionOfAcceptableUncertainty %>%anti_join(data.frame(Level_2="Vehicle")) %>%filter(KeptTemperature) %>% dplyr::select(Level_1 , Level_2, x, y) , by=c("Level_1", "x"), suffix =c("_Vehicle", "_TTT") ) %>%distinct() # remove repeated temperatures like the first and last. ######## final number of temperatures kept for ABC computation ######## N_temp <- data_for_ABC_computation %>%group_by(Level_1)%>%distinct() %>%summarise(N_temp_kept =n_distinct(x)) %>%mutate(N_temp_total =unique(RegionOfAcceptableUncertainty_N_temp$N_temp_total))######## absolute ABC ######## abs_ABC <- data_for_ABC_computation %>%# compute the abs diff between these fits, at temperatures at which both fits are certainmutate(Abs_diff =abs(y_Vehicle-y_TTT)) %>% dplyr::rename("Temperature"="x") %>%group_by(Level_1) %>%# approximate the integral from itgroup_modify(~ComputeIntegral(.x, .y),.keep =TRUE) %>%ungroup()######## signed ABC ######## signed_ABC <- data_for_ABC_computation %>%# compute the diff between these fits, at temperatures at which both fits are certainmutate(Abs_diff = y_TTT-y_Vehicle) %>%# the name here is just for the use of ComputeIntegral dplyr::rename("Temperature"="x") %>%group_by(Level_1) %>%# compute the integral from itgroup_modify(~ComputeIntegral(.x, .y),.keep =TRUE) %>%ungroup()######## combined signed and full ######## ABC <-full_join( abs_ABC %>% dplyr::rename("abs_ABC"="SimpsonInt"), signed_ABC %>% dplyr::rename("signed_ABC"="SimpsonInt") ) %>%full_join(N_temp)head(ABC)
The p-value computed from the subset of 16 IDs cannot be used here, because we used a dataset_wise approximation with 10 samples per IDs only, leading to a null distribution approximation of size \(16 \times 10 = 160\). This is too little for a reliable estimate of the p-values.
Instead, for the sake of the example, we propose to use the published p-values.
We first recompute the BH adjusted p-values while considering all proteins in the dataset.
Consequently, we subset p_values_fulldataset to only the 16 IDs of interest and merge the pvalues and adjusted p-values with the Nextflow results.
Code
p_values_df <-left_join(# remove the p-values computed from the subset p_values_subset %>% dplyr::select(-pValue, -size_null_distribution_approximation, -n_values_as_extreme_in_null_distribution_approximation),# add p-values computed on the full dataset, using 10 samples per ID and 4772 IDs. p_values_fulldataset %>% dplyr::select(Level_1, pValue, size_null_distribution_approximation, n_values_as_extreme_in_null_distribution_approximation, p_adj))
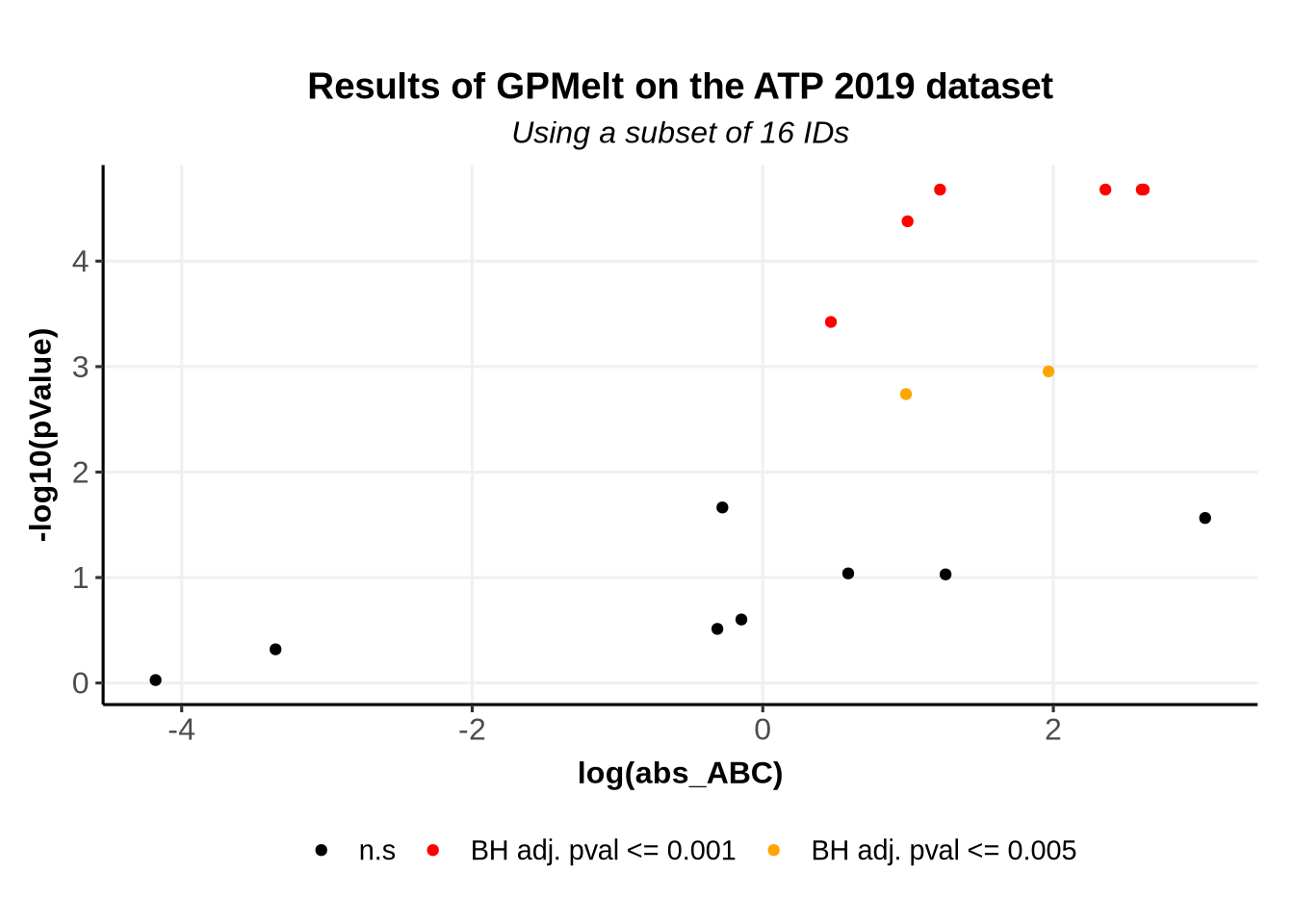
7 Volcano-like plots
We previously have computed the effect size, and have a measure of significance thanks to \(\Lambda\) and the p-values. We can plot these information in a Volcano plot, which typically represents the effect size and the p-values.
Code
BaseSize=12th1=0.001th2=0.005VolcanoPlot <-ggplot(p_values_df )+geom_point(aes(x =log(abs_ABC), y=-log10(pValue), color =ifelse(p_adj<=th1, "th1", ifelse(p_adj<=th2, "th2", "n.s")) , text = Level_1 ))+scale_color_manual(name ="", values=c("th1"="red","th2"="orange","n.s"="black"),labels =c("th1"=paste0("BH adj. pval <= ",th1 ),"th2"=paste0("BH adj. pval <= ",th2 ),"n.s"="n.s"))+ggtitle("Results of GPMelt on the ATP 2019 dataset",subtitle ="Using a subset of 16 IDs")+theme_Publication(base_size = BaseSize)print(VolcanoPlot)
8 A comparison between the absolute ABC and the signed ABC
We demonstrate here why these two metrics of the effect size are useful.
Using the published ABC computations saved on , under the name ATP2019/prerun/ABC_perID.rds, we add to our subset of 16 IDs the proteins RPLP0 and RPL5 and their p-values.
real_dataset_published <- real_dataset_published %>%mutate(rep =as.character(rep), # rep is a character in real_datasetLevel_3 =gsub("rep", "", Level_3)) # the names fo Level3 are slightly different.
As can be seen from this plot, some IDs lie on the dotted lines.
These dotted lines represent \(y=-x\) (left) and \(y=x\) (right).
IDs for which the points \((ABC, |ABC|)\) lies close to the line \(y=x\) are IDs for which the treatment condition remains (almost perfectly) uniformly above the control condition. We can talk about a stabilization effect of the treatment. This is the case of IMPDH1 (see figure below).
IDs for which the points \((ABC, |ABC|)\) lies close to the line \(y=-x\) are IDs for which the treatment condition remains (almost perfectly) uniformly below the control condition. We can talk about a destabilization effect of the treatment. This is the case of DDX50 (see figure below).
IDs with x values close to \(0\) but y values far from \(0\) correspond to IDs that would likely be overlooked if we would only use the \(ABC\)! If the \(ABC\) is about \(0\) but the \(|ABC|\) is large, then this means that the treatment and control conditions cross at least once (see RPL5 and RPLP0). This also means that at least one of these curves is likely non-sigmoidal. Defining the \(|ABC|\) makes it possible to notice these proteins with interesting patterns! Hence, do always use the \(|ABC|\) in your volcano plots!!
Note: As exemplified below with IMPDH1 and DDX50, non-sigmoidal melting curves can also be observed without any crossing of the melting curves!
Childs, Dorothee, Karsten Bach, Holger Franken, Simon Anders, Nils Kurzawa, Marcus Bantscheff, Mikhail M Savitski, and Wolfgang Huber. 2019. “Nonparametric Analysis of Thermal Proteome Profiles Reveals Novel Drug-Binding Proteins.”Molecular & Cellular Proteomics 18 (12): 2506–15.
Le Sueur, Cecile, Magnus Rattray, and Mikhail Savitski. 2024. “GPMelt: A Hierarchical Gaussian Process Framework to Explore the Dark Meltome of Thermal Proteome Profiling Experiments.”PLOS Computational Biology 20 (9): e1011632.
Savitski, Mikhail M, Friedrich BM Reinhard, Holger Franken, Thilo Werner, Maria Fälth Savitski, Dirk Eberhard, Daniel Martinez Molina, et al. 2014. “Tracking Cancer Drugs in Living Cells by Thermal Profiling of the Proteome.”Science 346 (6205): 1255784.